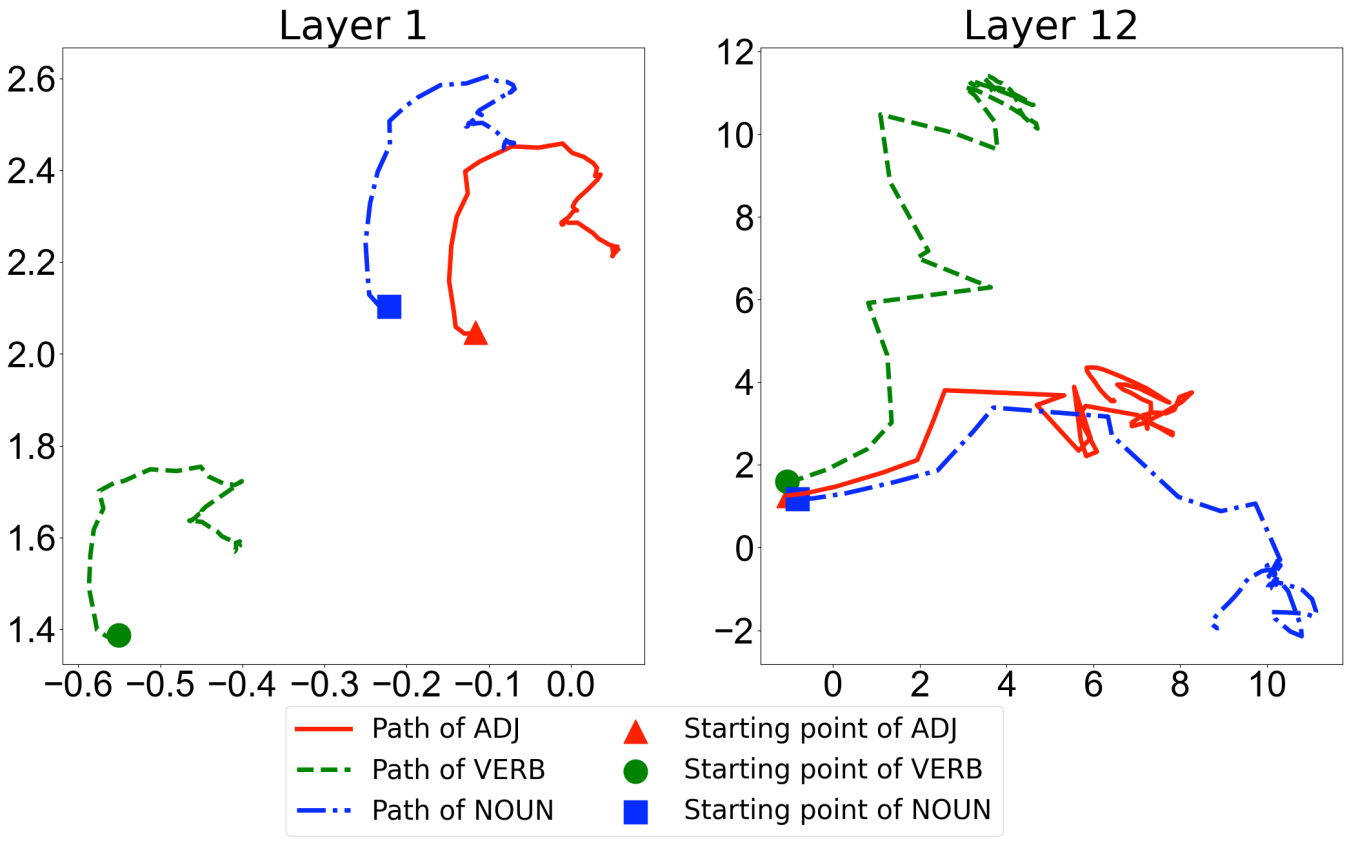
Given the prevalence of pre-trained contextualized representations in today’s NLP, there have been many efforts to understand what information they contain, and why they seem to be universally successful. The most common approach to use these representations involves fine-tuning them for an end task. Yet, how fine-tuning changes the underlying embedding space is less studied. In this work, we study the English BERT family and use two probing techniques to analyze how fine-tuning changes the space. We hypothesize that fine-tuning affects classification performance by increasing the distances between examples associated with different labels. We confirm this hypothesis with carefully designed experiments on five different NLP tasks. Via these experiments, we also discover an exception to the prevailing wisdom that “fine-tuning always improves performance”. Finally, by comparing the representations before and after fine-tuning, we discover that fine-tuning does not introduce arbitrary changes to representations; instead, it adjusts the representations to downstream tasks while largely preserving the original spatial structure of the data points.
@inproceedings{zhou-srikumar-2022-closer,title={A Closer Look at How Fine-tuning Changes {BERT}},author={Zhou, Yichu and Srikumar, Vivek},booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},month=may,year={2022},address={Dublin, Ireland},publisher={Association for Computational Linguistics},doi={10.18653/v1/2022.acl-long.75},pages={1046--1061}}
2021
Putting Words in BERT’s Mouth: Navigating Contextualized Vector Spaces with Pseudowords
We present a method for exploring regions around individual points in a contextualized vector space (particularly, BERT space), as a way to investigate how these regions correspond to word senses. By inducing a contextualized “pseudoword” vector as a stand-in for a static embedding in the input layer, and then performing masked prediction of a word in the sentence, we are able to investigate the geometry of the BERT-space in a controlled manner around individual instances. Using our method on a set of carefully constructed sentences targeting highly ambiguous English words, we find substantial regularity in the contextualized space, with regions that correspond to distinct word senses; but between these regions there are occasionally “sense voids”—regions that do not correspond to any intelligible sense.
@inproceedings{karidi-etal-2021-putting,title={Putting Words in {BERT}{'}s Mouth: Navigating Contextualized Vector Spaces with Pseudowords},author={Karidi, Taelin and Zhou, Yichu and Schneider, Nathan and Abend, Omri and Srikumar, Vivek},booktitle={Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing},month=nov,year={2021},address={Online and Punta Cana, Dominican Republic},publisher={Association for Computational Linguistics},doi={10.18653/v1/2021.emnlp-main.806},pages={10300--10313}}
DirectProbe: Studying Representations without Classifiers
In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Jun 2021
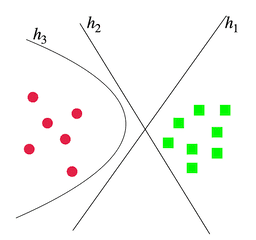
Understanding how linguistic structure is encoded in contextualized embedding could help explain their impressive performance across NLP. Existing approaches for probing them usually call for training classifiers and use the accuracy, mutual information, or complexity as a proxy for the representation’s goodness. In this work, we argue that doing so can be unreliable because different representations may need different classifiers. We develop a heuristic, DirectProbe, that directly studies the geometry of a representation by building upon the notion of a version space for a task. Experiments with several linguistic tasks and contextualized embeddings show that, even without training classifiers, DirectProbe can shine lights on how an embedding space represents labels and also anticipate the classifier performance for the representation.
@inproceedings{zhou-srikumar-2021-directprobe,title={{D}irect{P}robe: Studying Representations without Classifiers},author={Zhou, Yichu and Srikumar, Vivek},booktitle={Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},month=jun,year={2021},address={Online},publisher={Association for Computational Linguistics},doi={10.18653/v1/2021.naacl-main.401},pages={5070--5083},}
@article{zhou2020simple,title={A Simple Global Neural Discourse Parser},author={Zhou, Yichu and Koshorek, Omri and Srikumar, Vivek and Berant, Jonathan},journal={arXiv preprint arXiv:2009.01312},year={2020}}
2019
On the Limits of Learning to Actively Learn Semantic Representations
One of the goals of natural language understanding is to develop models that map sentences into meaning representations. However, training such models requires expensive annotation of complex structures, which hinders their adoption. Learning to actively-learn(LTAL) is a recent paradigm for reducing the amount of labeled data by learning a policy that selects which samples should be labeled. In this work, we examine LTAL for learning semantic representations, such as QA-SRL. We show that even an oracle policy that is allowed to pick examples that maximize performance on the test set (and constitutes an upper bound on the potential of LTAL), does not substantially improve performance compared to a random policy. We investigate factors that could explain this finding and show that a distinguishing characteristic of successful applications of LTAL is the interaction between optimization and the oracle policy selection process. In successful applications of LTAL, the examples selected by the oracle policy do not substantially depend on the optimization procedure, while in our setup the stochastic nature of optimization strongly affects the examples selected by the oracle. We conclude that the current applicability of LTAL for improving data efficiency in learning semantic meaning representations is limited.
@inproceedings{koshorek-etal-2019-limits,title={On the Limits of Learning to Actively Learn Semantic Representations},author={Koshorek, Omri and Stanovsky, Gabriel and Zhou, Yichu and Srikumar, Vivek and Berant, Jonathan},booktitle={Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL)},month=nov,year={2019},address={Hong Kong, China},publisher={Association for Computational Linguistics},doi={10.18653/v1/K19-1042},pages={452--462}}
Beyond Context: A New Perspective for Word Embeddings
Most word embeddings today are trained by optimizing a language modeling goal of scoring words in their context, modeled as a multi-class classification problem. In this paper, we argue that, despite the successes of this assumption, it is incomplete: in addition to its context, orthographical or morphological aspects of words can offer clues about their meaning. We define a new modeling framework for training word embeddings that captures this intuition. Our framework is based on the well-studied problem of multi-label classification and, consequently, exposes several design choices for featurizing words and contexts, loss functions for training and score normalization. Indeed, standard models such as CBOW and fasttext are specific choices along each of these axes. We show via experiments that by combining feature engineering with embedding learning, our method can outperform CBOW using only 10% of the training data in both the standard word embedding evaluations and also text classification experiments.
@inproceedings{zhou-srikumar-2019-beyond,title={Beyond Context: A New Perspective for Word Embeddings},author={Zhou, Yichu and Srikumar, Vivek},booktitle={Proceedings of the Eighth Joint Conference on Lexical and Computational Semantics (*{SEM} 2019)},month=jun,year={2019},address={Minneapolis, Minnesota},publisher={Association for Computational Linguistics},doi={10.18653/v1/S19-1003},pages={22--32}}